每经编辑:毕陆名
光计算在AI领域呈现高速的发展,具有广阔的应用前景。近日,中国科学院半导体研究团队研制出一款超高集成度光学卷积处理器。这标志着我国在光计算方面有了重大突破。
 (资料图片仅供参考)
(资料图片仅供参考)
中信建投更是直接喊出此项技术的突破在AI领域具有广阔前景。以Lightmatter和Lightelligence为代表的公司,推出了新型的硅光计算芯片,性能远超目前的AI算力芯片,据Lightmatter的数据,他们推出的Envise芯片的运行速度比英伟达的A100芯片快1.5到10倍。
中科院宣布重大科研成果
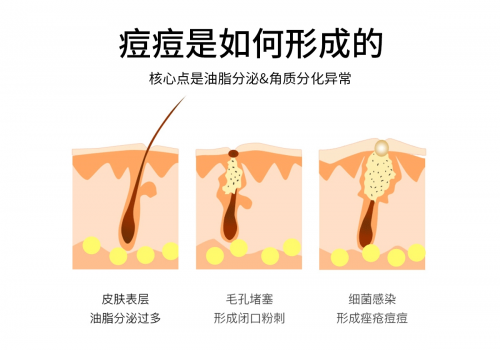
5月31日,中国科学院发布消息称,中国科学院半导体研究所集成光电子学国家重点实验室微波光电子课题组李明研究员-祝宁华院士团队研制出一款超高集成度光学卷积处理器。相关研究成果以Compact optical convolution processing unit based on multimode interference为题,发表在《自然-通讯》上。
这标志着我国在光计算方面有了重大突破。中信建投更是直接喊出此项技术的突破在AI领域具有广阔前景。据了解,光计算是一种利用光波作为载体进行信息处理的技术,具有大带宽、低延时、低功耗等优点,提供了一种“传输即计算,结构即功能”的计算架构,有望避免冯·诺依曼计算范式中存在的数据潮汐传输问题。
中信建投指出,近年来光计算在AI领域呈现高速的发展,具有广阔的应用前景。以Lightmatter和Lightelligence为代表的公司,推出了新型的硅光计算芯片,性能远超目前的AI算力芯片,据Lightmatter的数据,他们推出的Envise芯片的运行速度比英伟达的A100芯片快1.5到10倍。
5月17日举行的第五届中国硅光产业论坛上,国家信息光电子创新中心总经理肖希表示,硅光芯片不仅要加强在光传输、光互联上的应用,还要在光交换、光感知、光加密、光计算上发力,开发面向6G时代的下一代硅光技术。
目前,硅光芯片在所有芯片类型中增速最高,预测到2027年左右,基于硅光芯片的光模块占比将超过50%。
图片来源:视觉中国
AMD推出“终极武器”MI300X
光芯片能够挑战英伟达的AI芯片吗?
美东时间6月13日周二,AMD举行了新品发布会,其中最重磅的新品当属性用于训练大模型的ADM最先进GPU Instinct MI300。
AMD CEO苏姿丰介绍,生成式AI和大语言模型(LLM)需要电脑的算力和内存大幅提高。她预计,今年,数据中心AI加速器的市场将达到300亿美元左右,到2027年将超过1500亿美元,复合年增长率超过50%。
苏姿丰演示介绍,AMD的Instinct MI300A号称全球首款针对AI和高性能计算(HPC)的加速处理器(APU)加速器。在13个小芯片中遍布1460亿个晶体管。
它采用CDNA 3 GPU架构和24个Zen 4 CPU内核,配置128GB的HBM3内存。相比前代MI250,MI300的性能提高八倍,效率提高五倍。AMD在发布会稍早介绍,新的Zen 4c内核比标准的Zen 4内核密度更高,比标准Zen 4的内核小35%,同时保持100%的软件兼容性。
图片来源:每日经济新闻 资料图
AMD推出一款GPU专用的MI300,即MI300X,该芯片是针对LLM的优化版,拥有192GB的HBM3内存、5.2TB/秒的带宽和896GB/秒的Infinity Fabric带宽。AMD将1530亿个晶体管集成在共12个5纳米的小芯片中。
AMD称,MI300X提供的HBM密度最高是英伟达AI芯片H100的2.4倍,其HBM带宽最高是H100的1.6倍。这意味着,AMD的芯片可以运行比英伟达芯片更大的模型。
苏姿丰介绍,MI300X可以支持400亿个参数的Hugging Face AI模型运行,并演示了让这个LLM写一首关于旧金山的诗。这是全球首次在单个GPU上运行这么大的模型。单个MI300X可以运行一个参数多达800亿的模型。
AMD还发布了AMD Instinct平台,它拥有八个MI300X,采用行业标准OCP设计,提供总计1.5TB的HBM3内存。苏姿丰称,适用于CPU和GPU的版本MI300A现在就已出样,MI300X和八个GPU的Instinct平台将在今年第三季度出样,第四季度正式推出。
除了AI芯片,AMD此次发布会还介绍了第四代EPYC(霄龙)处理器,特别是在全球可用的云实例方面的进展。AMD称,第四代EPYC(霄龙)启用新的Zen 4c内核,比英特尔Xeon 8490H的效率高1.9倍。由于绝大多数AI在CPU上运行,AMD在CPU AI领域具有绝对的领先优势。
每日经济新闻综合中国科学院、AMD新品发布会、中信建投
每日经济新闻返回搜狐,查看更多